The first step is to get a list of url to crawl and then extracting data from them. Let’s have a look at reading HTML pages and extracting data from them The simplest way to do this is by using the bs4 library.
This serie of article is not related to python, but a cool way to experiment is to use IPython notebook. I’m using the below address to code python anywhere 🙂
We are going to do two things:
- gettting a full page
- extract url from it
!pip install bs4
import urllib.request as urllib2
from bs4 import BeautifulSoup
response = urllib2.urlopen('https://en.wikipedia.org/')
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Formating the parsed html files
print(soup.title)
print(soup.title.string)
print(soup.a.string)
print(soup.b.string)
for x in soup.find_all('a', href=True):
print ("Found the URL:", x['href'])
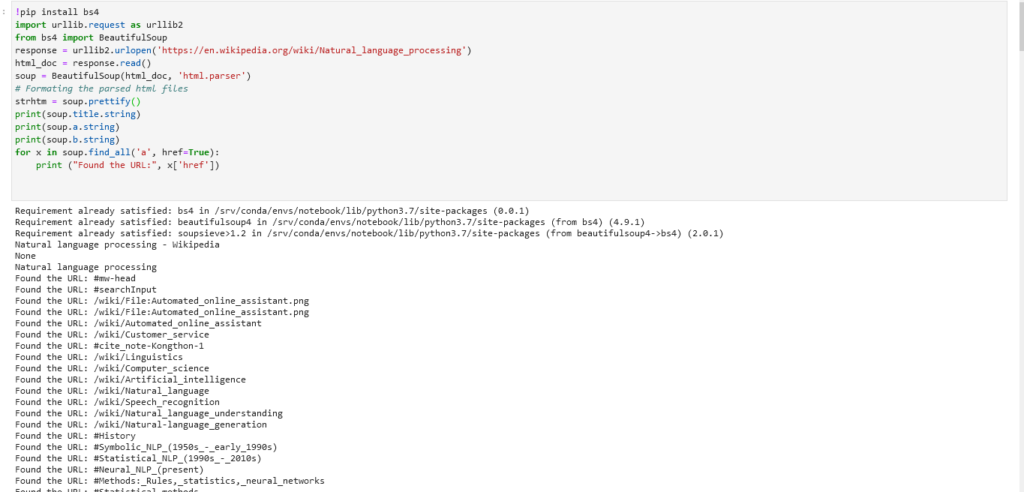
As you see there are a lot of uninteresting links, that either are internals or are images. So we need to filter the unusable links. So we can define the following architecture.
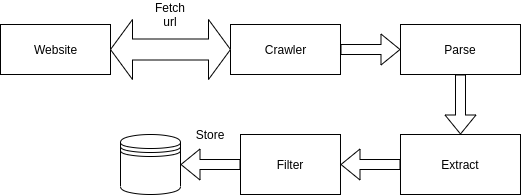
A good start for filtering is to use regular expression and python provides a good framework for that. Python provides also a good liray to parse the url themselves.
Let’s take our example:
!pip install bs4
import re
import urllib.request as urllib2
import urllib.parse as urlparse
from bs4 import BeautifulSoup
response = urllib2.urlopen('https://en.wikipedia.org/')
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Formating the parsed html files
pat = re.compile("https?://")
for x in soup.find_all('a', href=True):
if pat.match(x['href']):
print(urlparse.urlparse(x['href']))
Right now we only print the resulting url, now let’s try to store them into a database. There’s a good library in python for document oriented database called TinyDB. This library is like a sqllight. The database itself is saved inside a file. This library is okay for small projects but for bigger project you need to use a “true” database.
Now our objective is :
- extract all url from a page
- store theses urls inside a database
- use this database again and again to inject new url
!pip install bs4
!pip install tinydb
import datetime
from tinydb import TinyDB, Query
from tinydb.storages import MemoryStorage
import urllib3
import re
import urllib.request as urllib2
import urllib.parse as urlparse
from bs4 import BeautifulSoup
def crawlUrl(url,status):
response = urllib2.urlopen(url)
try:
print('Trying')
response = urllib2.urlopen(url)
except IOError:
print ('Error during crawling!')
return
db=TinyDB(storage=MemoryStorage)
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Bootstrap the database
pat = re.compile("https?://")
for x in soup.find_all('a', href=True):
if pat.match(x['href']) and x['href'][1]!= '': db.update_or_insert({'url':x['href'],'domain':urlparse.urlparse(x['href'])')
#db.insert({'url':x['href'],'domain':urlparse.urlparse(x['href'])
body=""
for y in soup.find_all('p',):
body+=y
db.truncate()
crawlUrl('https://curlie.org/en/Reference/Knowledge_Management/Knowledge_Discovery/Software',0)
User = Query()
for i in db.search(User.status == 0):
#print (i)
crawlUrl (i['url'],1)
for i in db.search(User.status == 1):
print(i)
for i in db.search(User.status == 0):
print(i)
Now we ha list of url, and this list was created by the generation of an url.
Now the objectoive is to understand what thgere are inside. The first easy way to do that is to get all <p> tags inside the page and analyze the content.
from bs4 import BeautifulSoup
import datetime
from tinydb import TinyDB, Query
import urllib3
import xlsxwriter
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
url = 'https://elpaso.craigslist.org/search/mcy?sort=date'
total_added = 0
def make_soup(url):
http = urllib3.PoolManager()
r = http.request("GET", url)
return BeautifulSoup(r.data,'lxml')
def main(url):
global total_added
db = TinyDB("db.json")
while url:
print ("Web Page: ", url)
soup = soup_process(url, db)
nextlink = soup.find("link", rel="next")
url = False
if (nextlink):
url = nextlink['href']
print ("Added ",total_added)
make_excel(db)
def soup_process(url, db):
global total_added
soup = make_soup(url)
results = soup.find_all("li", class_="result-row")
for result in results:
try:
rec = {
'pid': result['data-pid'],
'date': result.p.time['datetime'],
'cost': clean_money(result.a.span.string.strip()),
'webpage': result.a['href'],
'pic': clean_pic(result.a['data-ids']),
'descr': result.p.a.string.strip(),
'createdt': datetime.datetime.now().isoformat()
}
Result = Query()
s1 = db.search(Result.pid == rec["pid"])
if not s1:
total_added += 1
print ("Adding ... ", total_added)
db.insert(rec)
except (AttributeError, KeyError) as ex:
pass
return soup
def clean_money(amt):
return amt.replace("$","")
def clean_pic(ids):
idlist = ids.split(",")
first = idlist[0]
code = first.replace("1:","")
return "https://images.craigslist.org/%s_300x300.jpg" % code
def make_excel(db):
Headlines = ["Pid", "Date", "Cost", "Webpage", "Pic", "Desc", "Created Date"]
row = 0
workbook = xlsxwriter.Workbook('motorcycle.xlsx')
worksheet = workbook.add_worksheet()
worksheet.set_column(0,0, 15) # pid
worksheet.set_column(1,1, 20) # date
worksheet.set_column(2,2, 7) # cost
worksheet.set_column(3,3, 10) # webpage
worksheet.set_column(4,4, 7) # picture
worksheet.set_column(5,5, 60) # Description
worksheet.set_column(6,6, 30) # created date
for col, title in enumerate(Headlines):
worksheet.write(row, col, title)
for item in db.all():
row += 1
worksheet.write(row, 0, item['pid'] )
worksheet.write(row, 1, item['date'] )
worksheet.write(row, 2, item['cost'] )
worksheet.write_url(row, 3, item['webpage'], string='Web Page')
worksheet.write_url(row, 4, item['pic'], string="Picture" )
worksheet.write(row, 5, item['descr'] )
worksheet.write(row, 6, item['createdt'] )
workbook.close()
main(url)
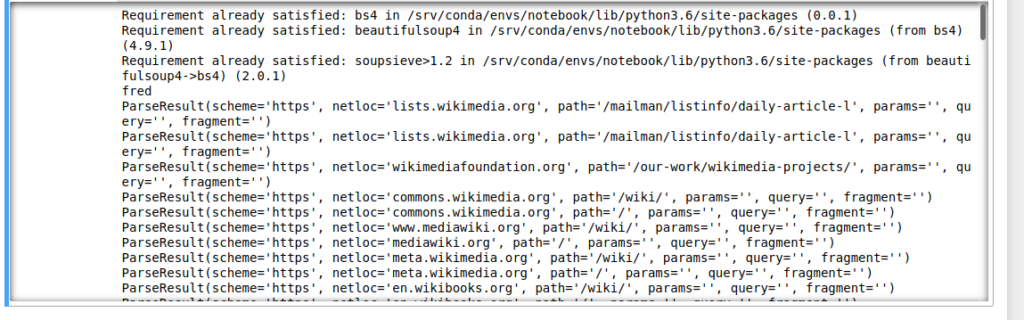
If we go deeper, we have a lot of interesting information related to a link:the title, the alt text,…