Hi all,
SSE usage is a bit tricky
You have to see see registers as vectorial not a linear and their size is depending of the context.
For instance xmm0 (a SSE 128 bytes register)can be seen as 2*64 bits register or 4*32 bits register or 8*16 bits register or 16*8 bits register.
So what is the aim of this ?
If you want to add two arrays the algorithm wil be
int x [4] ; //let's say that sizeof(int) =32 int y[4]; int z[4]; c[0]=a[0]b[0] c[1]=a[1]+b[1] c[2]=a[2]+b[2] c[3]=a[3]+b[3]
In assembler it gives :
.loc 1 6 0
mov edx, DWORD PTR [rbp-48]
mov eax, DWORD PTR [rbp-32]
add eax, edx
mov DWORD PTR [rbp-16], eax
.loc 1 7 0
mov edx, DWORD PTR [rbp-44]
mov eax, DWORD PTR [rbp-28]
add eax, edx
mov DWORD PTR [rbp-12], eax
.loc 1 8 0
mov edx, DWORD PTR [rbp-40]
mov eax, DWORD PTR [rbp-24]
add eax, edx
mov DWORD PTR [rbp-8], eax
.loc 1 9 0
mov edx, DWORD PTR [rbp-36]
mov eax, DWORD PTR [rbp-20]
add eax, edx
mov DWORD PTR [rbp-4], eax
mov eax, 0
For instance c[0] = a[0]+b[0] is generated like that:
.loc 1 6 0
mov edx, DWORD PTR [rbp-48] ; a[0]
mov eax, DWORD PTR [rbp-32] ; b[0]
add eax, edx ;eax <- a[0]+b[0]
mov DWORD PTR [rbp-16], eax ; c[0] = eaz
And we are doing that 4 times. But thanks to the SSE extension operator we can do it with less instructions
The Streaming SIMD Extensions enhance the x86 architecture in four ways:
- 8 new 128-bit SIMD floating-point registers that can be directly addressed;
- 50 new instructions that work on packed floating-point data;
- 8 new instructions designed tocontrol cacheability of all MMX and 32-bit x86 data types, including the ability to stream data to memory without polluting the caches, and to prefetch data before it is actually used;
- 12 new instructions that extend the instruction set.
This set enables the programmer to develop algorithms that can mix packed, single-precision, floating-point and integer using both SSE and MMX instructions respectively.
Intel SSE provides eight 128-bit general-purpose registers, each of which can be directly addressed using the register names XMM0 to XMM7. Each register consists of four 32-bit single precision, floating-point numbers, numbered 0 through 3.
SSE instructions operate on either all or the least significant pairs of packed data operands in parallel. The packed instructions (with PS suffix) operate on a pair of operands, while scalar instructions (with SS suffix) always operate on the least significant pair of the two operands; for scalar operations, the three upper components from the first operand are passed through to the destination.
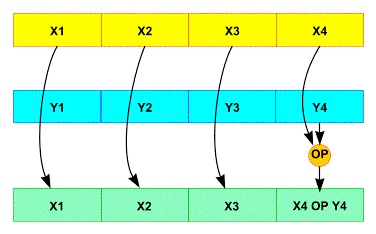
There are two ways to use SSE registers
Scalar the same 4 instructions on 4 datas
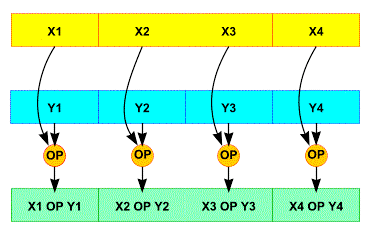
Packed
(thanks to Stefano Tommesani)
So let’s return to our code. I think you gonna understand where I want to go. I we fill two registers with 4 values (a[0]..a[3]) in one register and (c[0]..c[3]), add them together and put the result in a third register. With this solution we will do only one addition.
#include
#include
#include
void p128_hex_u8(__m128i in) {
uint8_t v[16];
_mm_store_si128((__m128i*)v, in);
printf("v16_u8: %x %x %x %x | %x %x %x %x | %x %x %x %x | %x %x %x %xn",
v[0], v[1], v[2], v[3], v[4], v[5], v[6], v[7],
v[8], v[9], v[10], v[11], v[12], v[13], v[14], v[15]);
}
void p128_hex_u16(__m128i in) {
uint16_t v[8];
_mm_store_si128((__m128i*)v, in);
printf("v8_u16: %x %x %x %x, %x %x %x %xn", v[0], v[1], v[2], v[3], v[4], v[5], v[6], v[7]);
}
void p128_hex_u32(__m128i in) {
uint32_t v[4] __attribute__((aligned (16)));
_mm_store_si128((__m128i*)v, in);
printf("v4_u32: %x %x %x %xn", v[0], v[1], v[2], v[3]);
}
void p128_dec_u32(__m128i in) {
uint32_t v[4] __attribute__((aligned (16)));
_mm_store_si128((__m128i*)v, in);
printf("v4_u32: %d %d %d %dn",(uint32_t) v[0], (uint32_t) v[1], (uint32_t)v[2],(uint32_t) v[3]);
}
void p128_hex_u64(__m128i in) {
long long v[2]; // uint64_t might give format-string warnings with %llx; it's just long in some ABIs
_mm_store_si128((__m128i*)v, in);
printf("v2_u64: %llx %llxn", v[0], v[1]);
}
int main(){
uint32_t a [4] ={1,2,3,4}; //let's say that sizeof(int) = 32
uint32_t b[4] = {11,12,13,14};
uint32_t c[4];
c[0]=a[0]+b[0];
c[1]=a[1]+b[1];
c[2]=a[2]+b[2];
c[3]=a[3]+b[3];
printf("Result %d %d %d %dn",c[0],c[1],c[2],c[3]);
__m128i a1 = _mm_set_epi32(a[3], a[2], a[1], a[0]);
__m128i b1 = _mm_set_epi32(b[3], b[2], b[1], b[0]);
__m128i c1 = _mm_add_epi32(a1, b1);
p128_dec_u32(a1);
p128_dec_u32(b1);
p128_dec_u32(c1);
}
This a very simple example, as your compiler can already optimize your code with this