Preimage attack on Keccak-512 reduced to 8 rounds, requiring 2511.5 time and 2508 memory[2]
Zero-sum distinguishers exist for the full 24-round Keccak-f[1600], though they cannot be used to attack the hash function itself[3]
SHA-3 (Secure Hash Algorithm 3) is the latest member of the Secure Hash Algorithm family of standards, released by NIST on August 5, 2015.[4][5] The reference implementation source code was dedicated to public domain via CC0 waiver.[6] Although part of the same series of standards, SHA-3 is internally quite different from the MD5-like structure of SHA-1 and SHA-2.
SHA-3 is a subset of the broader cryptographic primitive family Keccak (/ˈkɛtʃæk/, or /ˈkɛtʃɑːk/),[7][8] designed by Guido Bertoni, Joan Daemen, Michaël Peeters, and Gilles Van Assche,
Keccak is based on a novel approach called sponge construction. Sponge construction is based on a wide random function or random permutation, and allows inputting (“absorbing” in sponge terminology) any amount of data, and outputting (“squeezing”) any amount of data, while acting as a pseudorandom function with regard to all previous inputs. This leads to great flexibility.
SHA-3 uses the sponge construction,[13][23] in which data is “absorbed” into the sponge, then the result is “squeezed” out. In the absorbing phase, message blocks are XORed into a subset of the state, which is then transformed as a whole using a permutation function f. In the “squeeze” phase, output blocks are read from the same subset of the state, alternated with the state transformation function f. The size of the part of the state that is written and read is called the “rate” (denoted r), and the size of the part that is untouched by input/output is called the “capacity” (denoted c). The capacity determines the security of the scheme. The maximum security level is half the capacity.
Given an input bit string N, a padding function pad, a permutation function f that operates on bit blocks of width b, a rate r and an output length d, we have capacity c = b − r and the sponge construction Z = sponge[f,pad,r](N,d), yielding a bit string Z of length d, works as follows:[24]:18
pad the input N using the pad function, yielding a padded bit string P with a length divisible by r (such that n = len(P)/r is integer),
break P into n consecutive r-bit pieces P0, …, Pn-1
initialize the state S to a string of b 0 bits.
absorb the input into the state: For each block Pi,
extend Pi at the end by a string of c 0 bits, yielding one of length b,
XOR that with S and
apply the block permutation f to the result, yielding a new state S
initialize Z to be the empty string
while the length of Z is less than d:
append the first r bits of S to Z
if Z is still less than d bits long, apply f to S, yielding a new state S.
truncate Z to d bits
The fact that the internal state S contains c additional bits of information in addition to what is output to Z prevents the length extension attacks that SHA-2, SHA-1, MD5 and other hashes based on the Merkle–Damgård construction are susceptible to.
In SHA-3, the state S consists of a 5 × 5 array of w = 64-bit words, b = 5 × 5 × w = 5 × 5 × 64 = 1600 bits total. Keccak is also defined for smaller power-of-2 word sizes w down to 1 bit (25 bits total state). Small state sizes can be used to test cryptanalytic attacks, and intermediate state sizes (from w = 8, 200 bits, to w = 32, 800 bits) can be used in practical, lightweight applications.[11][12]
For SHA-3-224, SHA-3-256, SHA-3-384, and SHA-3-512 instances, r is greater than d, so there is no need for additional block permutations in the squeezing phase; the leading d bits of the state are the desired hash. However, SHAKE-128 and SHAKE-256 allow an arbitrary output length, which is useful in applications such as optimal asymmetric encryption padding.
Padding
To ensure the message can be evenly divided into r-bit blocks, padding is required. SHA-3 uses the pattern 10*1 in its padding function: a 1 bit, followed by zero or more 0 bits (maximum r − 1) and a final 1 bit.
The maximum of r − 1 0 bits occurs when the last message block is r − 1 bits long. Then another block is added after the initial 1 bit, containing r − 1 0 bits before the final 1 bit.
The two 1 bits will be added even if the length of the message is already divisible by r.[24]:5.1 In this case, another block is added to the message, containing a 1 bit, followed by a block of r − 2 0 bits and another 1 bit. This is necessary so that a message with length divisible by r ending in something that looks like padding does not produce the same hash as the message with those bits removed.
The initial 1 bit is required so messages differing only in a few additional 0 bits at the end do not produce the same hash.
The position of the final 1 bit indicates which rate r was used (multi-rate padding), which is required for the security proof to work for different hash variants. Without it, different hash variants of the same short message would be the same up to truncation.
The block permutation
The block transformation f, which is Keccak-f[1600] for SHA-3, is a permutation that uses xor, and and not operations, and is designed for easy implementation in both software and hardware.
It is defined for any power-of-two word size, w = 2ℓ bits. The main SHA-3 submission uses 64-bit words, ℓ = 6.
The state can be considered to be a 5 × 5 × w array of bits. Let a[i][ j][k] be bit (5i + j) × w + k of the input, using a little-endian bit numbering convention and row-major indexing. I.e. i selects the row, j the column, and k the bit.
Index arithmetic is performed modulo 5 for the first two dimensions and modulo w for the third.
The basic block permutation function consists of 12 + 2ℓ rounds of five steps, each individually very simple:
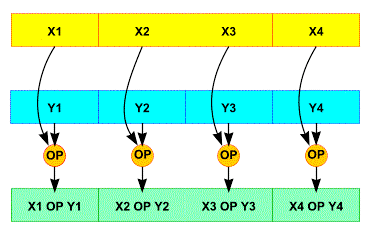
θ
Compute the parity of each of the 5w (320, when w = 64) 5-bit columns, and exclusive-or that into two nearby columns in a regular pattern. To be precise, a[i][ j][k] ← a[i][ j][k] ⊕ parity(a[0…4][ j−1][k]) ⊕ parity(a[0…4][ j+1][k−1])
ρ
Bitwise rotate each of the 25 words by a different triangular number 0, 1, 3, 6, 10, 15, …. To be precise, a[0][0] is not rotated, and for all 0 ≤ t < 24, a[i][ j][k] ← a[i][ j][k−(t+1)(t+2)/2], where ( i j ) = ( 3 2 1 0 ) t ( 0 1 ) {\displaystyle {\begin{pmatrix}i\\j\end{pmatrix}}={\begin{pmatrix}3&2\\1&0\end{pmatrix}}^{t}{\begin{pmatrix}0\\1\end{pmatrix}}} {\begin{pmatrix}i\\j\end{pmatrix}}={\begin{pmatrix}3&2\\1&0\end{pmatrix}}^{t}{\begin{pmatrix}0\\1\end{pmatrix}}.
π
Permute the 25 words in a fixed pattern. a[j][2i+3j] ← a[ i][j].
χ
Bitwise combine along rows, using x ← x ⊕ (¬y & z). To be precise, a[i][ j][k] ← a[i][ j][k] ⊕ (¬a[i][ j+1][k] & a[i][ j+2][k]). This is the only non-linear operation in SHA-3.
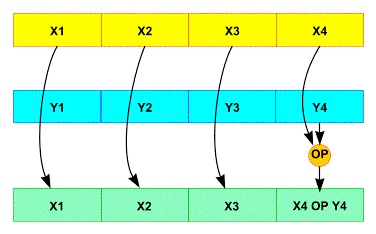
ι
Exclusive-or a round constant into one word of the state. To be precise, in round n, for 0 ≤ m ≤ ℓ, a[0][0][2m−1] is exclusive-ORed with bit m + 7n of a degree-8 LFSR sequence. This breaks the symmetry that is preserved by the other steps.
Speed
The speed of SHA-3 hashing of long messages is dominated by the computation of f = Keccak-f[1600] and XORing S with the extended Pi, an operation on b = 1600 bits. However, since the last c bits of the extended Pi are 0 anyway, and XOR with 0 is a noop, it is sufficient to perform XOR operations only for r bits (r = 1600 − 2 × 224 = 1152 bits for SHA3-224, 1088 bits for SHA3-256, 832 bits for SHA3-384 and 576 bits for SHA3-512). The lower r is (and, conversely, the higher c = b − r = 1600 − r), the less efficient but more secure the hashing becomes since fewer bits of the message can be XORed into the state (a quick operation) before each application of the computationally expensive f.
Keccak[c](N, d) = sponge[Keccak-f[1600], pad10*1, r](N, d)[24]:20
Keccak-f[1600] = Keccak-p[1600, 24][24]:17
c is the capacity
r is the rate = 1600 − c
N is the input bit string