This a new serie of article to see how to create a your own search engine.
We will cover all fields from start to end necessary to create a good. Before that let’s get some vocabulary and
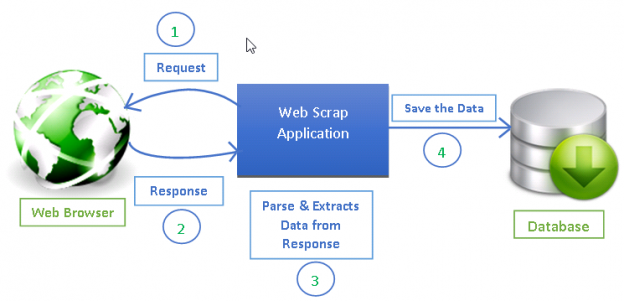
Crawling means the action to get a web page or document, either to store it into memory or into a database. The most easy way to do it is to implement it in Python. Indeed in this case performance are not critical as the bottleneck is the network.
After the craw, you have to analyze the page or the document. Depending of the source you can extract different useful information. For a web page you can get the title, the description. If you know the kind of source you can attach values to the document to add better value. We will call this part parsing. Then you store this documents in a database
Indexing means you have a lot of different source of document and you want to link them together to answer to the user query. The main objective is to create score.
Query parsing is the only “dynamic” part. It gets input form the user, try to understand it and returns the best results. You can add value by using the previously requested query. For instance imagine the first query was “trip to new york”, and the second “hotel reservation”. For the second query according to the first you can imagine that the user search for an hotel in New York.
Each of theses parts can be done independently. During this serie of tutorial I will show how theses parts work. Nowadays python gives a lot of good libraries for NPL, I will use some of them to simplify the code and it’s a waste of time to try to re-code theses libraries.
As a result here’s a full process.