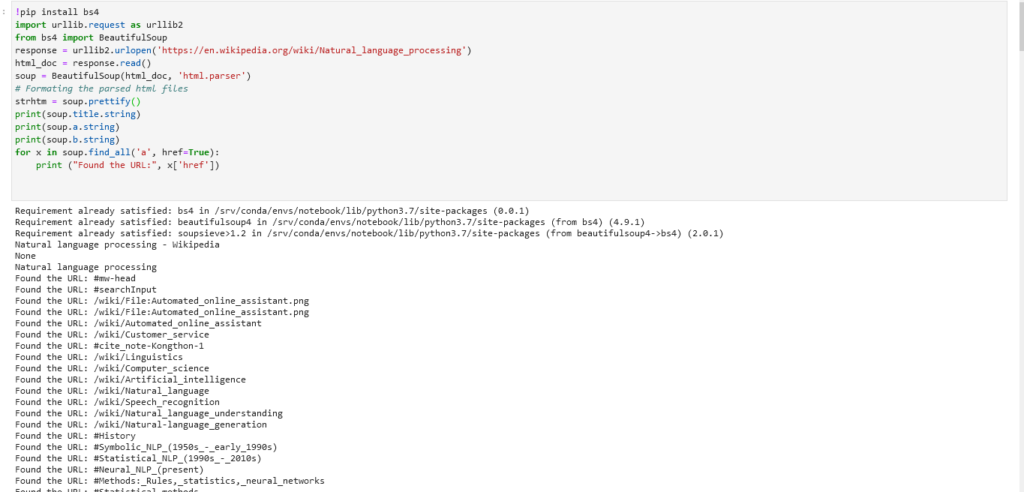
The first step is to get a list of url to crawl and then extracting data from them. Let’s have a look at reading HTML pages and extracting data from them The simplest way to do this is by using the bs4 library.
This serie of article is not related to python, but a cool way to experiment is to use IPython notebook. I’m using the below address to code python anywhere 🙂
!pip install bs4
import urllib.request as urllib2
from bs4 import BeautifulSoup
response = urllib2.urlopen('https://en.wikipedia.org/')
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Formating the parsed html files
print(soup.title)
print(soup.title.string)
print(soup.a.string)
print(soup.b.string)
for x in soup.find_all('a', href=True):
print ("Found the URL:", x['href'])
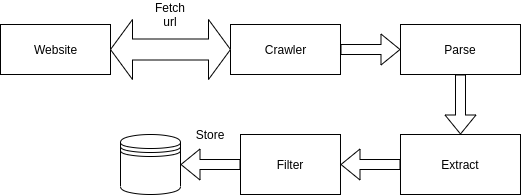
As you see there are a lot of uninteresting links, that either are internals or are images. So we need to filter the unusable links. So we can define the following architecture.
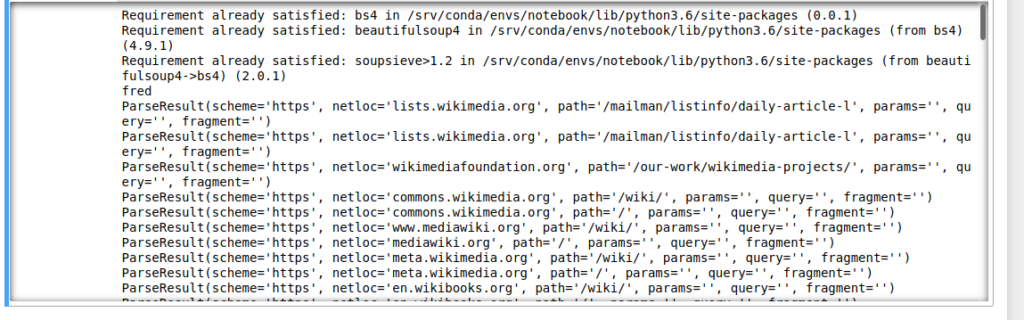
A good start for filtering is to use regular expression and python provides a good framework for that. Python provides also a good liray to parse the url themselves.
Let’s take our example:
!pip install bs4
import re
import urllib.request as urllib2
import urllib.parse as urlparse
from bs4 import BeautifulSoup
response = urllib2.urlopen('https://en.wikipedia.org/')
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Formating the parsed html files
pat = re.compile("https?://")
for x in soup.find_all('a', href=True):
if pat.match(x['href']):
print(urlparse.urlparse(x['href']))
Right now we only print the resulting url, now let’s try to store them into a database. There’s a good library in python for document oriented database called TinyDB. This library is like a sqllight. The database itself is saved inside a file. This library is okay for small projects but for bigger project you need to use a “true” database.
Now our objective is :
extract all url from a page
store theses urls inside a database
use this database again and again to inject new url
!pip install bs4
!pip install tinydb
import datetime
from tinydb import TinyDB, Query
from tinydb.storages import MemoryStorage
import urllib3
import re
import urllib.request as urllib2
import urllib.parse as urlparse
from bs4 import BeautifulSoup
def crawlUrl(url,status):
response = urllib2.urlopen(url)
try:
print('Trying')
response = urllib2.urlopen(url)
except IOError:
print ('Error during crawling!')
return
db=TinyDB(storage=MemoryStorage)
html_doc = response.read()
soup = BeautifulSoup(html_doc, 'html.parser')
# Bootstrap the database
pat = re.compile("https?://")
for x in soup.find_all('a', href=True):
if pat.match(x['href']) and x['href'][1]!= '': db.update_or_insert({'url':x['href'],'domain':urlparse.urlparse(x['href'])')
#db.insert({'url':x['href'],'domain':urlparse.urlparse(x['href'])
body=""
for y in soup.find_all('p',):
body+=y
db.truncate()
crawlUrl('https://curlie.org/en/Reference/Knowledge_Management/Knowledge_Discovery/Software',0)
User = Query()
for i in db.search(User.status == 0):
#print (i)
crawlUrl (i['url'],1)
for i in db.search(User.status == 1):
print(i)
for i in db.search(User.status == 0):
print(i)
Now we ha list of url, and this list was created by the generation of an url.
Now the objectoive is to understand what thgere are inside. The first easy way to do that is to get all <p> tags inside the page and analyze the content.
This a new serie of article to see how to create a your own search engine.
We will cover all fields from start to end necessary to create a good. Before that let’s get some vocabulary and
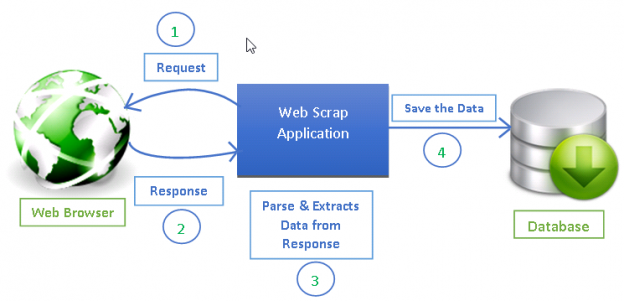
Crawling means the action to get a web page or document, either to store it into memory or into a database. The most easy way to do it is to implement it in Python. Indeed in this case performance are not critical as the bottleneck is the network.
After the craw, you have to analyze the page or the document. Depending of the source you can extract different useful information. For a web page you can get the title, the description. If you know the kind of source you can attach values to the document to add better value. We will call this part parsing. Then you store this documents in a database
Indexing means you have a lot of different source of document and you want to link them together to answer to the user query. The main objective is to create score.
Query parsing is the only “dynamic” part. It gets input form the user, try to understand it and returns the best results. You can add value by using the previously requested query. For instance imagine the first query was “trip to new york”, and the second “hotel reservation”. For the second query according to the first you can imagine that the user search for an hotel in New York.
Each of theses parts can be done independently. During this serie of tutorial I will show how theses parts work. Nowadays python gives a lot of good libraries for NPL, I will use some of them to simplify the code and it’s a waste of time to try to re-code theses libraries.
On Ubuntu 18.04 it will install the Cuda version 9.
Vocabulary
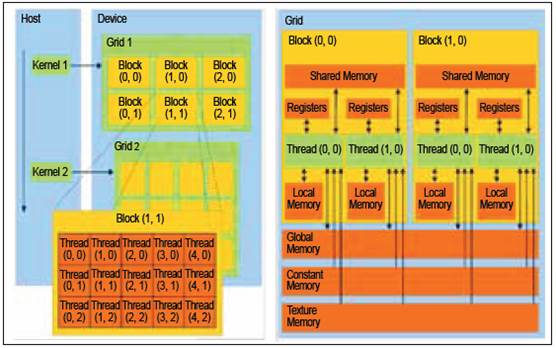
A small definition of concept is necessary to understand the CUDA architecture. Host An another word to say the CPU of the running machine. Device: The GPU itself Kernel Function or portion of code that runs on a grid GridSet of blocks BlocksSet of threads ThreadsSmallest unit of execution
Ouch.
Surprisingly the smallest unit of a GPU is called a thread (so a different meaning from Linux vocabulary) but the power of a GPU os it can start all threads in one or two instruction and synchronization is done directly on the card, whithout any intervention from the developer.
Example
To use this new concept, the Nvidia add new directive or keywords in the C++ syntax. To use them you must use the Nvidia compiler nvcc.
CUDA C keyword __global__ indicates that a function runs on the device called from host code (value by default to execute a kernel on a GPU)
CUDA C keyword __device__ indicates that a function runs on the device called from a device code
CUDA C keyword __host__ indicates that a function runs on the host (the main CPU)
After all theses consideration, let’s start with a small example.
#include "performancetiming.hpp"
#include
#include
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<24; // 16M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 16M elements on the CPU
add(N, x, y);
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
This code is adding number one by one all elements of two arrays and store it in the second. The main processing part is done in add function. Each result is independent so we can
Using the I can now choose which implementation of algorithm we can use for a specific task and how efficient are the optimization provided
The official keccak gives a list of several implementation (they can be found here https://keccak.team/software.html) The aim of this article is to evaluate them, try to optimize them and choose the fastest one.
as you’ve already know I’ve developed a small library to asset performance of code. The aim of this library is to objectively report how long a function last. It would help you choose an implementation of an algorithm for example. To illustrate that I will take fibonnaci function as an example. I know at least two implementations of this function, one functional and an another iterative. The strong point of the functional version is that it is easier to implement and to understand as contrary to the iterative. But for large number I suspect the functional version to be very slow but I can not say to what point.
int __inline__ fibonacci(int n)
{
if (n < 3)
return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int __inline__ fibonacciOptim(int n)
{
int first = 0, second = 1, next, c;
for (c = 0; c < n; c++)
{
if (c <= 1)
next = c;
else
{
next = first + second;
first = second;
second = next;
}
}
return next;
}
It is now time to use the Timing Library First clone the repository
git clone https://github.com/fflayol/timingperf.git
cd timingperf
Then create a main to set values of the library and add the different version of your code:
#include "performancetiming.hpp"
int __inline__ fibonacci(int n)
{
if (n < 3)
return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int __inline__ fibonacciOptim(int n)
{
int first = 0, second = 1, next, c;
for (c = 0; c < n; c++)
{
if (c <= 1)
next = c;
else
{
next = first + second;
first = second;
second = next;
}
}
return next;
}
int main(int argc, char **argv)
{
timing::addFunction("FIB", fibonacci);
timing::addFunction("FIB-OPTIM", fibonacciOptim);
timing::setTimingFunction(2);
timing::setNumberExecution(1000000);
timing::Execute(15);
timing::CalcResult();
}
The result gives:
fflayol@local:~/Perso/timingperf$ ./ex1.out
Begin [ FIB ]
End [ FIB ]
Begin [ FIB-OPTIM ]
End [ FIB-OPTIM ]
Begin [ FIB ]
End [ FIB ]
Begin [ FIB-OPTIM ]
End [ FIB-OPTIM ]
fflayol@local:~/Perso/timingperf$ ./ex1.out
Begin [ FIB ] End [ FIB ]
Begin [ FIB-OPTIM ] End [ FIB-OPTIM ]
Begin [ FIB ] End [ FIB ]
Begin [ FIB-OPTIM ] End [ FIB-OPTIM ]
The difference here is very important because our optimization version is 40x faster 🙂 An another nice feature is to check compiler optimization quality. You can change the compiler optimization with -O option followed by a numer (0 to 3, the higher the better).
As a result both version are faster (3x for the functional version and 5x with the iterative version). As a result the difference of performance is still higher.
If you have a look around in the web, a solution to correctly measure time is to use a new C++ package: std::chrono , which is part of the standard C++ library.
So the aim of this article is to investigate if this solution can be used to have a very high resolution timer. If you remember well as we are doing small improvement we want to be able to measure the improvement (or degradation). of optimization.
First step is to
#include <chrono>
#include <ratio>
#include <climits>
#include <algorithm> // std::max
int main()
{
long long value = 0;
double max = LONG_MIN ;
double min = LONG_MAX;
for (int i= 1;i<100;i++){
auto startInitial = std::chrono::high_resolution_clock::now();
auto endInitial = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::nano > elapsedInitial = (endInitial - startInitial) ;
max = std::max(max,elapsedInitial.count());
min = std::min(min,elapsedInitial.count());
value=value+elapsedInitial.count();
}
std::cout <<"Sum for 100 loop"<<value<<" " <<value/100<<"ns"std::endl;
std::cout<<" Max:" <<max <<"ns Min:"<<min<<"ns"<<std::endl;
}
fflayol@:/tmp$ g++ test1.c -std=c++11;./a.out
Sum for 100 loop: 2235
Mean: 22ns
Max : 53ns
Min : 21ns
This example shows that the call last at means 20ns which is quite too long for our purpose.
Indeed if we are trying to be more accurate:
#include <iostream>
#include <chrono>
#include <ratio>
#include <climits>
#include <algorithm> // std::max
int main()
{
{
long long value = 0;
double max = LONG_MIN ;
double min = LONG_MAX;
for (int i= 1;i<100;i++){
auto startInitial = std::chrono::high_resolution_clock::now();
auto endInitial = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::nano > elapsedInitial = (endInitial - startInitial) ;
max = std::max(max,elapsedInitial.count());
min = std::min(min,elapsedInitial.count());
value=value+elapsedInitial.count();
}
std::cout <<"Sum for 100 loop"<<value<<" " <<value/100<<"ns"<<std::endl;
std::cout<<" Max:" <<max <<"ns Min:"<<min<<"ns"<<std::endl;
}
std::cout <<"Second function"<<std::endl;
{
long long value = 0;
double max = LONG_MIN ;
double min = LONG_MAX;
for (int i= 1;i<100;i++){
auto startInitial = std::chrono::high_resolution_clock::now();
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
asm("nop");
auto endInitial = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::nano > elapsedInitial = (endInitial - startInitial) ;
max = std::max(max,elapsedInitial.count());
min = std::min(min,elapsedInitial.count());
value=value+elapsedInitial.count();
}
std::cout <<"Sum for 100 loop"<<value<<" " <<value/100<<"ns"<<std::endl;
std::cout<<" Max:" <<max <<"ns Min:"<<min<<"ns"<<std::endl;
}
}